🧠 Serverless Scales

In Part 1: What is Serverless? I talked about how one of the biggest pros to a serverless architecture is how well it scales and how high availability is baked in.
In this post I’ll go over:
- How a traditional highly available scalable architecture works
- How a scalable serverless architecture works
- How you can benefit from a serverless architecture
Firstly, I would like to address that I am not advocating that a serverless architecture is always better than a traditional architecture. Each have their purpose. In this article I will be highlighting how you can benefit from a serverless architecture.
Traditional Highly Available Scalable Architecture
In a traditional highly available scalable architecture, a developer or architect, will have to think about many key components:
- Networks & Availability Zones
- Load Balancers
- Scaling Triggers
- Security (ex: DMZ or Web layer that handles authentication/authorization)
Most commonly, these components are put together to create what is known as an N-Tier or Multitier Architecture. Below I will talk about a 2 and 3 tier architectures to highlight their differences and complexities. This will help us better understand how a serverless architecture can simplify a highly available scalable architecture solution.
2 Tier Architecture
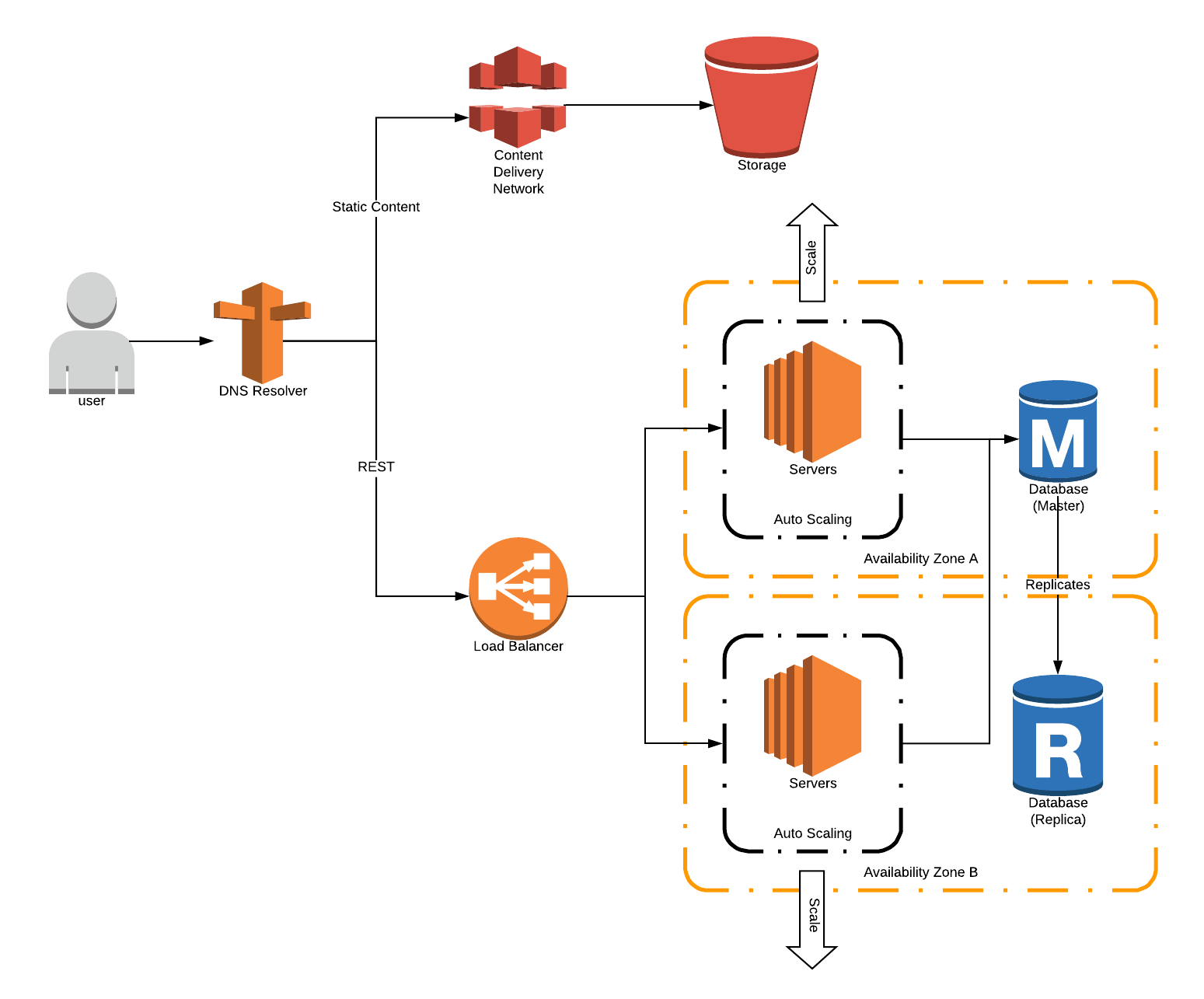
In this simple 2 tier architecture, you’ll notice we already have to account for a load balancer, and at least 2 availability zones to make this a highly available application. To be even safer, many would argue you want to have 3 availability zones, with least 3 servers always running. This will make sure that even during a zero downtime deployment your application stays highly available.
This 2-tier architecture still doesn’t address security concerns like a DMZ/Web layer. For these reasons, most organizations will implement what is known as a 3-tier architecture. In order to implement this we must add another load balancer, and another layer of applications.
3 Tier Architecture
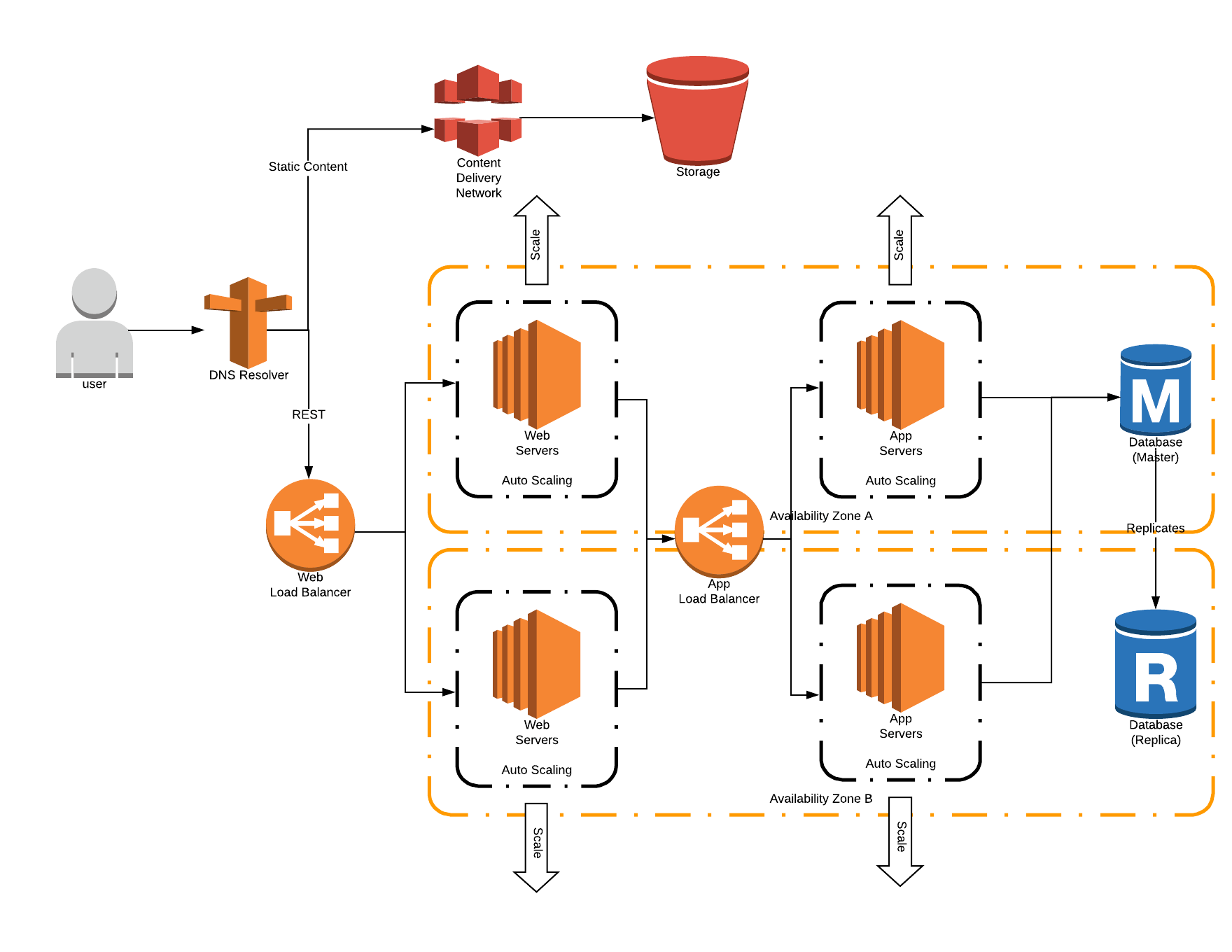
In this common 3-tier architecture we have added 1 more load balancer, and at least 3 more servers. By doing so, we have added many key benefits to our architecture including a DMZ/Web layer and scaling at both Web & App layers. However, we have also increased the complexity of our system roughly by 2.
Serverless Architecture
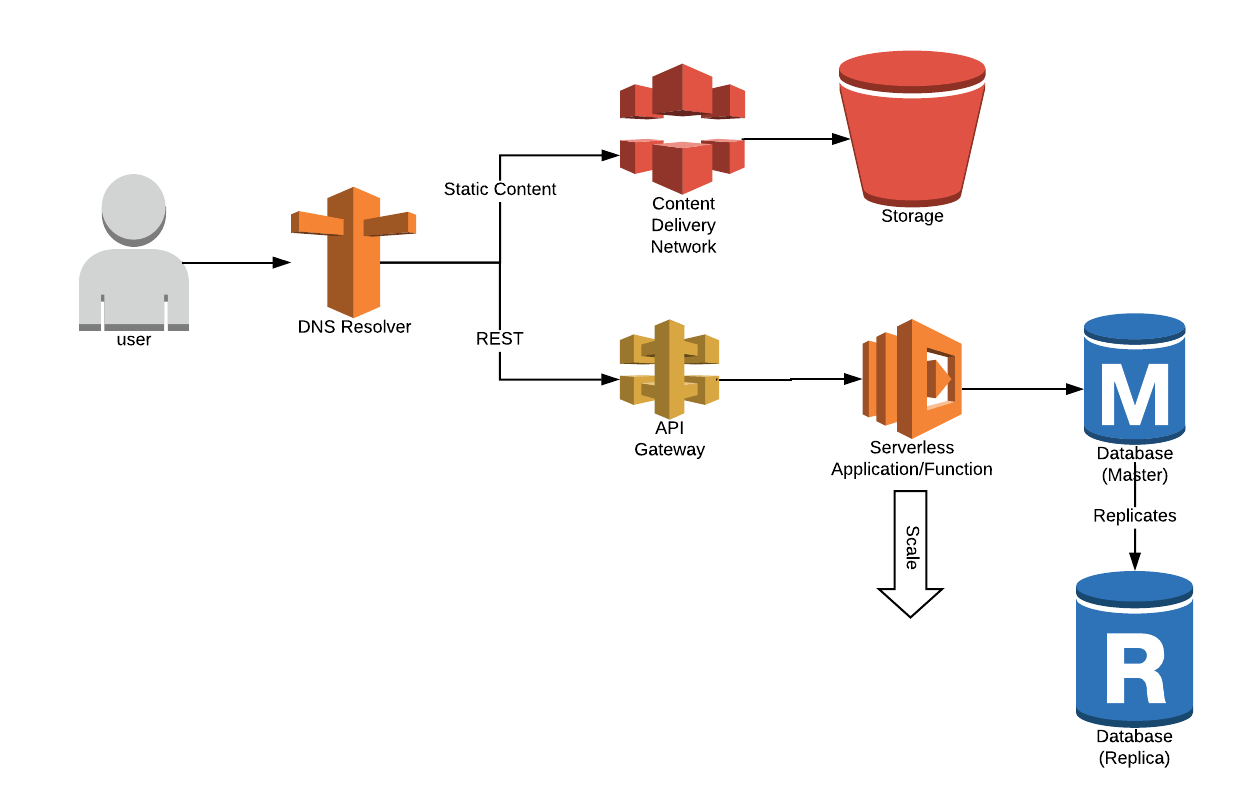
By using a serverless architecture (like shown above), we have removed the complexity of availability zones, load balancers, scaling triggers and a DMZ. The nature of the serverless function is that the high availability responsibility is now managed by the cloud provider.
Now you might be asking about security, and how that got lost. The API gateway, will handle authentication and authorization with some extra configuration. The fact that the serverless functions are created and destroyed on each execution, means attackers cannot infect your servers, since you essentially have none.
Granted, there still might be vulnerabilities that have not been make public or patched that attackers can still exploit, however, the responsibility of keeping the platform secure is now the cloud providers responsibility.
Further, you still could have security flaws in your application that allow it to leak data, but this is an application issue, and not an architecture issue.
How you can benefit
As we can see from above, by using a serverless architecture, we can benefit in many ways
- Baked in high availability
- Reduced complexity
- Costs
Costs are something I have not yet covered, since they can be a double edged sword. To get a deep dive on serverless costs, make sure you read Part 3: Serverless Costs where I analyze when to use a serverless architecture for cost benefits. However, for most web applications, you will see a significant cost reduction, especially if usage is infrequent or sporadic.
Summary
In conclusion, there are many benefits such as reduced complexity, baked in high availability, and reduced costs when using a serverless architecture. Make sure to check out the next post in this series Part 3: Serverless Costs where I dive deep into the costs of serverless.